
Recognizing what we do or what we will do has been well investigated under action recognition and anticipation literature in the Computer Vision (CV) and Machine Learning (ML) research communities. However, computational learning of why do we do what we do is not well investigated. The objective of this project is to develop Artificial Intelligent (AI) models to process videos and learn why do humans do what they do? by reducing the gap between neural and symbolic representation through novel neurosymbolic AI. These neurosymbolic AI models can see what we do and then reason about our behavior to interpret, justify, explain and understand our actions.
Codes are also available here!Publications
| 2026 | |||
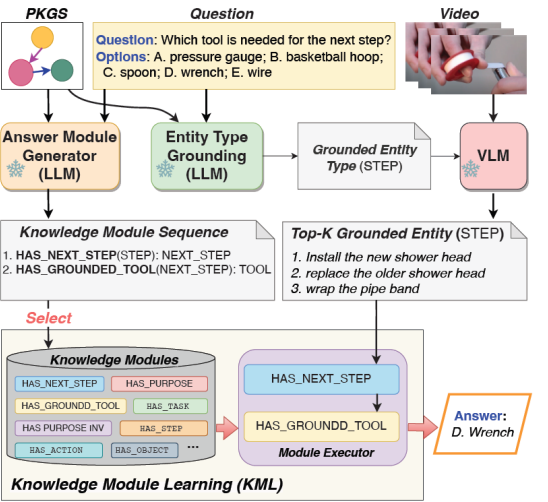 |
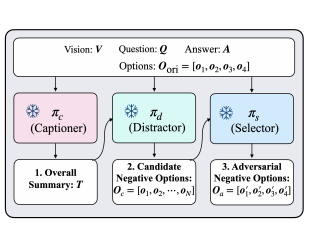
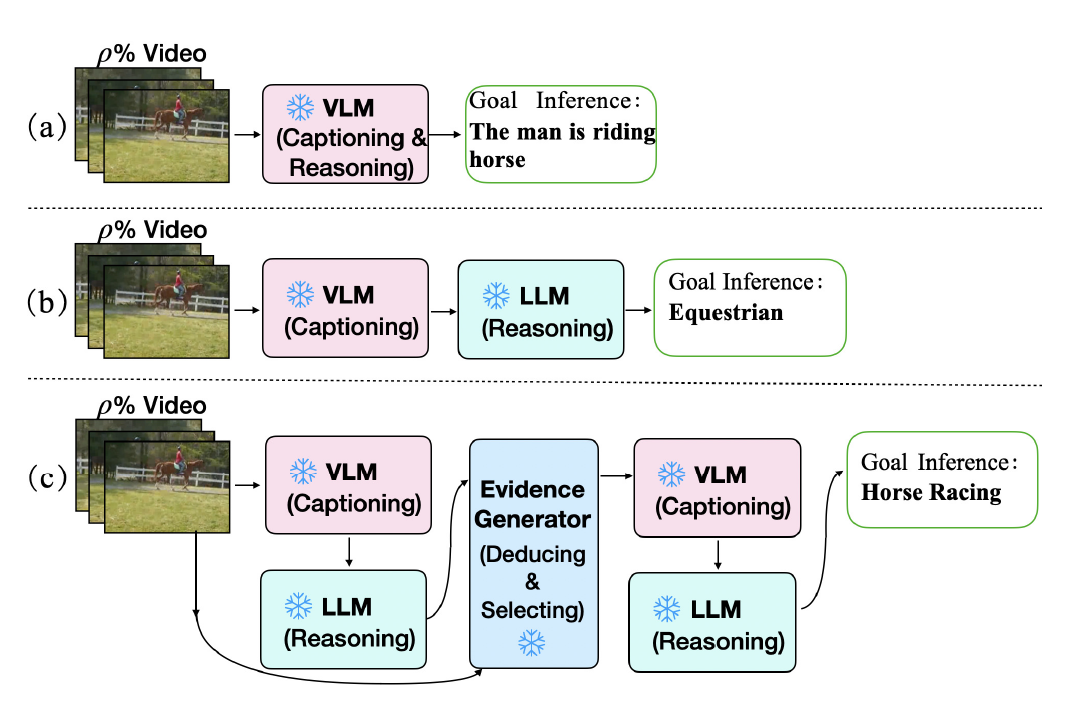
PKR-QA: A Benchmark for Procedural Knowledge Reasoning with Knowledge Module Learning
AAAI 2026
PDF
| Extended Paper
| Code
|
||
 |
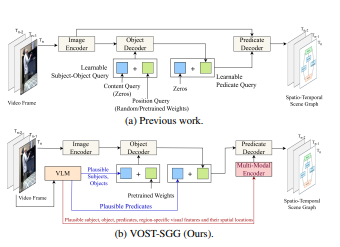
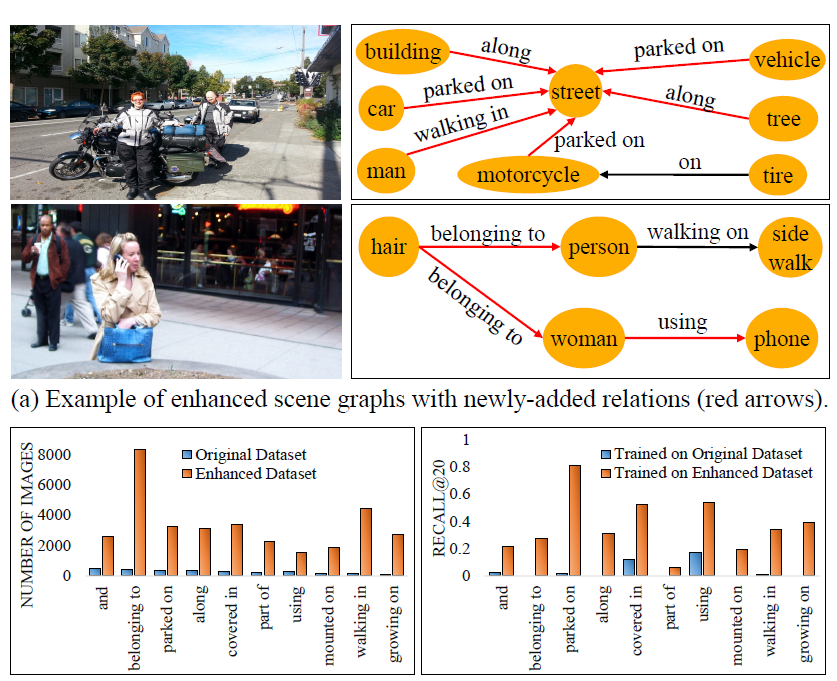
Know-Show: Benchmarking Video-Language Models on Spatio-Temporal Grounded Reasoning
Preprint
PDF
Dataset and codes
|
||
 |
|||
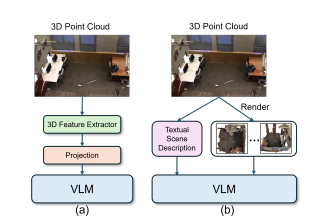 |
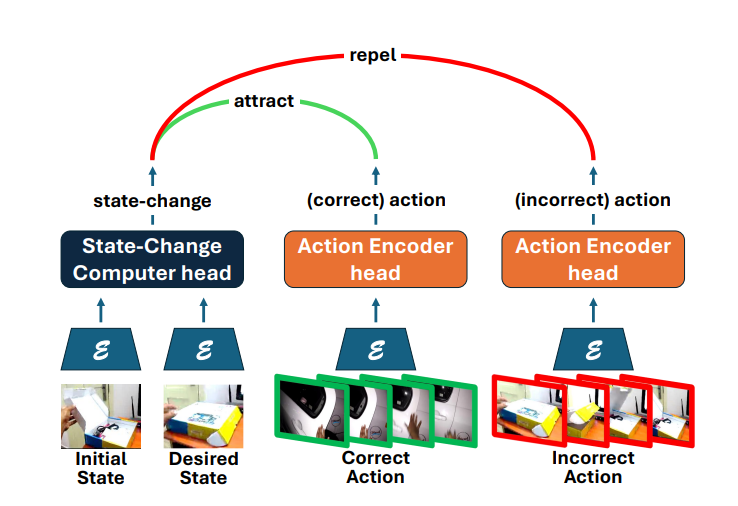
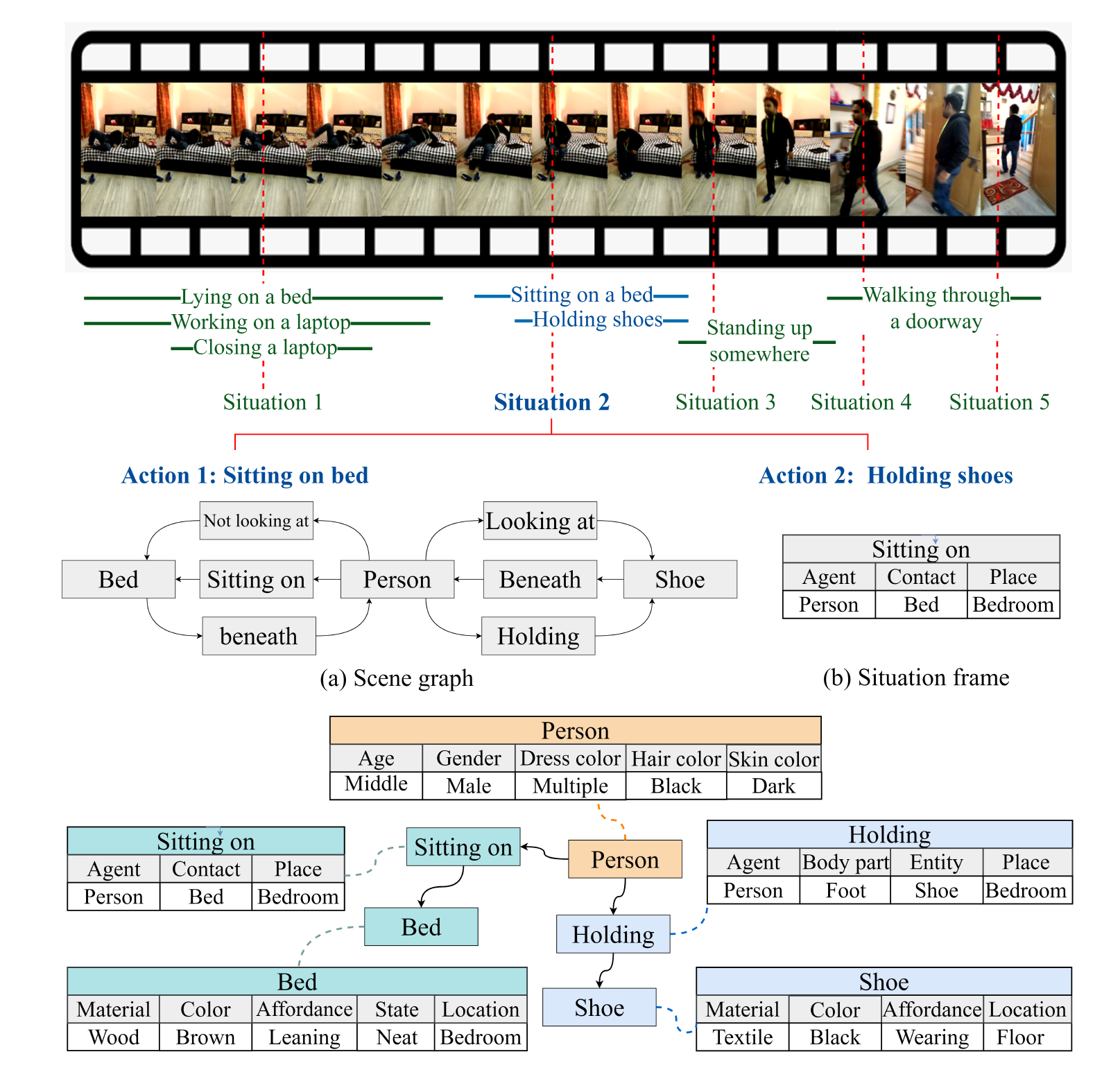
HMR3D: Hierarchical Multimodal Representation for 3D Scene Understanding with Large Vision-Language Model
Preprint
PDF
|
||
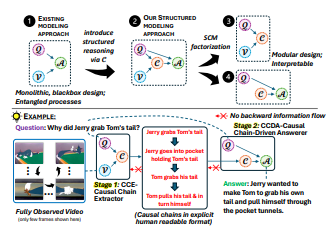 |
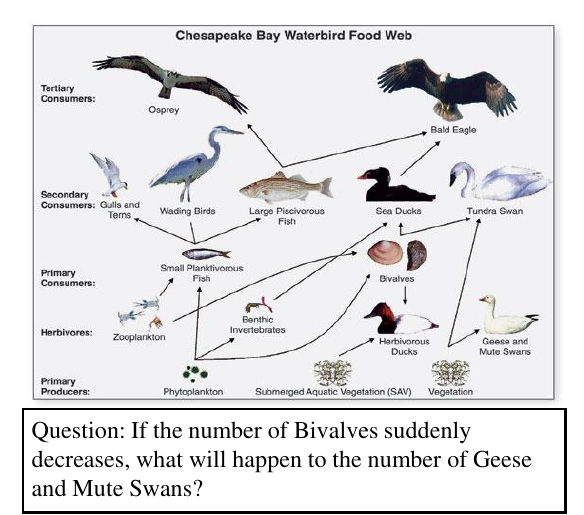
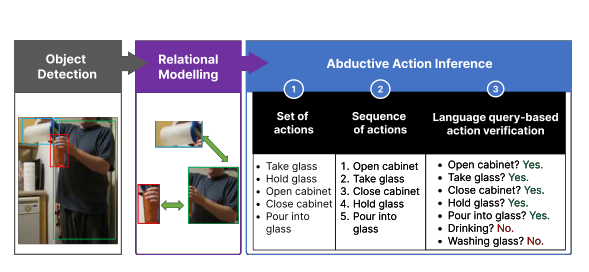
ChainReaction: Causal Chain-Guided Reasoning for Modular and Explainable Causal-Why Video Question Answering
Preprint
PDF
|
||
 |
|||
 |
|||
 |
|||
 |
|||
 |
|||
|
|||
|
|||
 |
|||
 |
|||
 |
|||
 |
|||
 |
|||
 |
|||
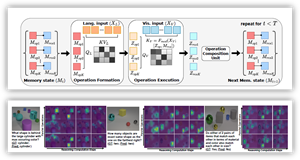 |
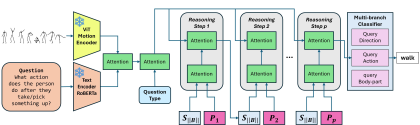
Learning to Reason Iteratively and Parallelly for Complex Visual Reasoning Scenarios
NeurIPS 2024 (Accepted)
PDF
code (soon)
|
||
 |
|||
 |
|||
 |
|||
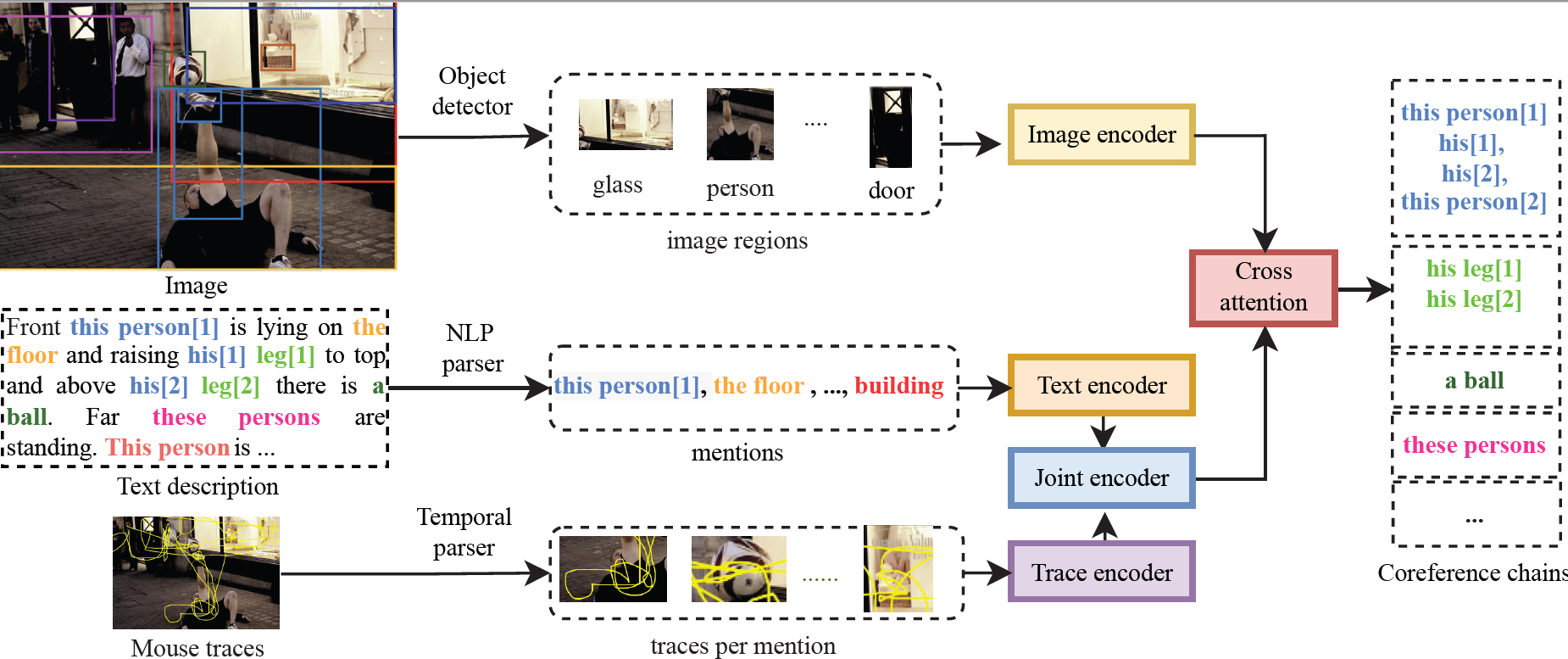 |
Who are you referring to? Coreference resolution in image narrations
International Conference on Computer Vision - ICCV (2023)
PDF
CIN Dataset
Code
Bibtex
|
||
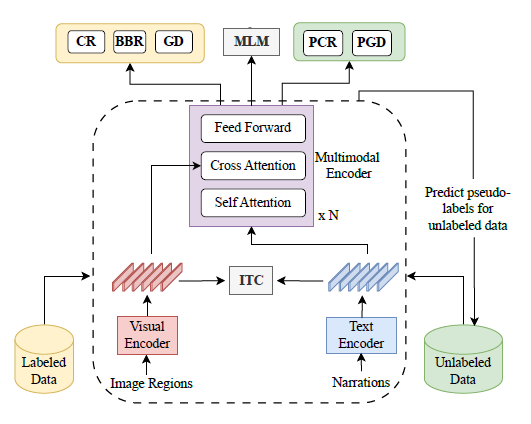 |
|||
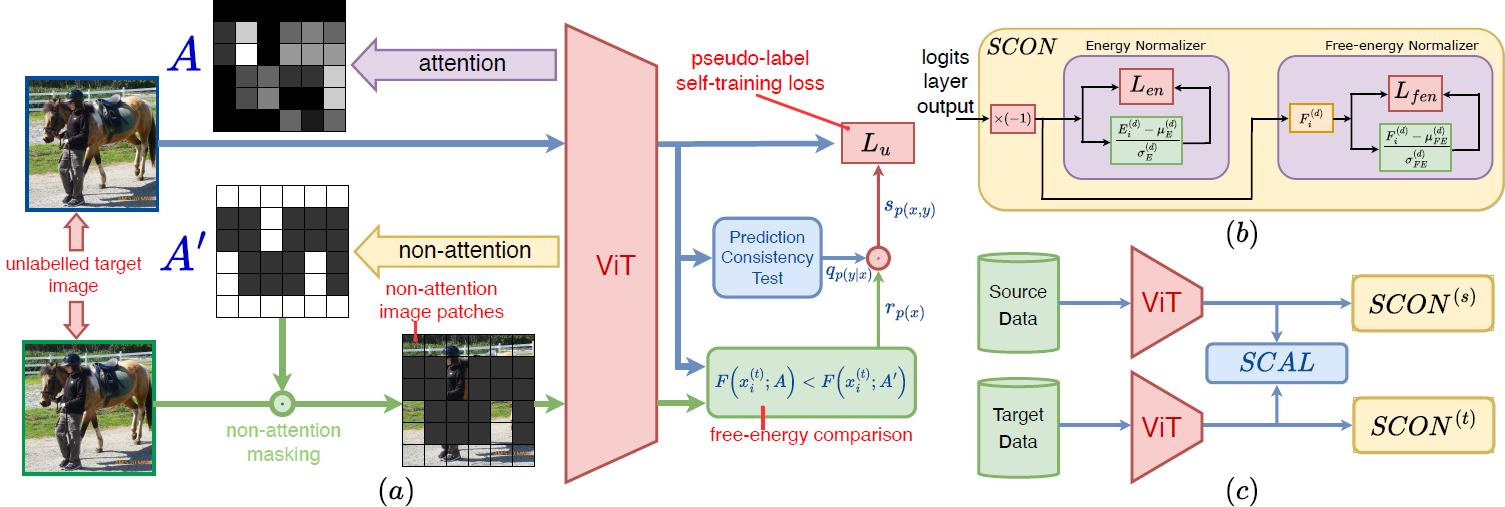 |
|||
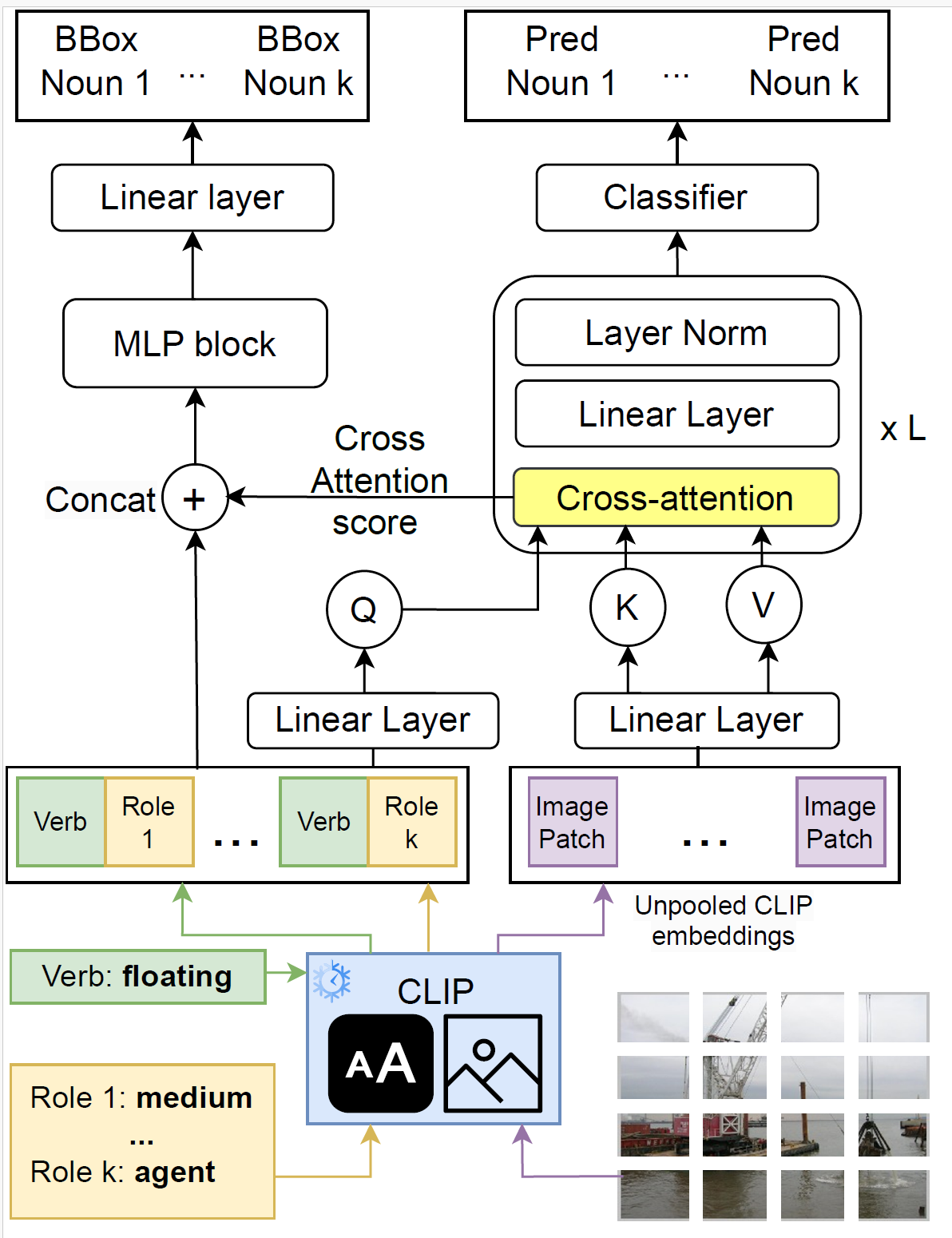 |
ClipSitu: Effectively Leveraging CLIP for Conditional Predictions in Situation Recognition
IEEE/CVF Winter Conference on Applications of Computer Vision - WACV (2024)
Best results in SWiG - 2024
Best results in imSitu - 2024
Code
PDF
Bibtex
|
||
 |
|||
 |
|||
 |